Deep Reinforcement Learning
Notes and topics inspired by the HuggingFace.co Deep Reinforcement tutorial series.
- Deep Reinforcement Learning
- Reinforcement Learning Framework
- Exploration / Exploitation tradeoff
- RL Agent’s brain: Policy π
- Overall provided summary
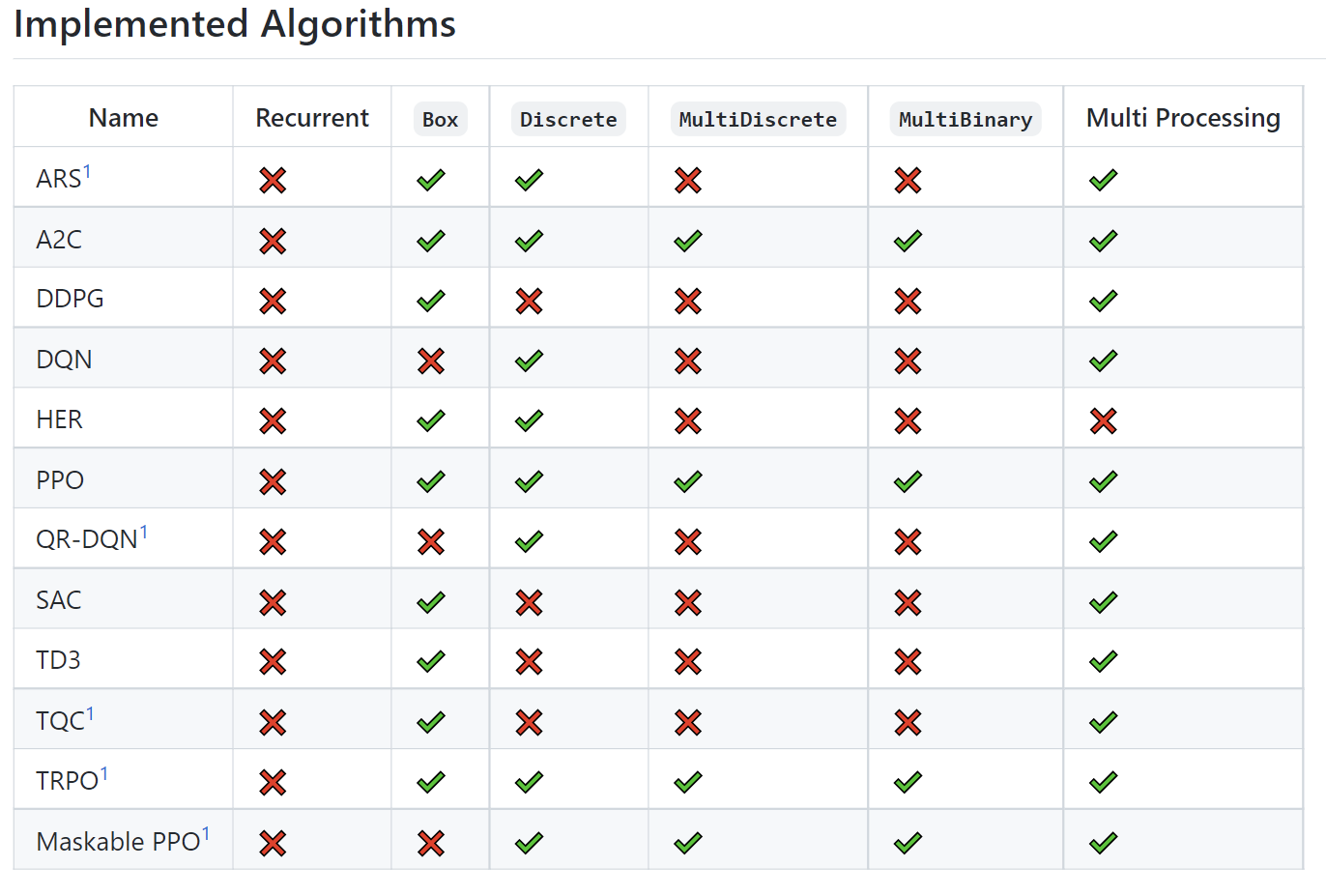
- Stable Baselines3
Deep Reinforcement Learning
- Deep RL is a subtype of machine learning where an agent learns how to behave in an environment by performing actions and observing the results.
- Overall idea is how an agent will learn from the environment by interacting with it and recieve rewards as feedback for performing actions.
- A formal definition states, “Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.”
Reinforcement Learning Framework
Overall Process
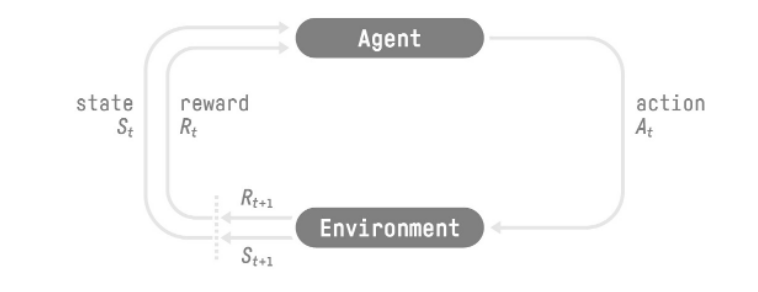 Basic architecture for RL
Basic architecture for RL
- Agent recieves State S0 from the Environment – we recieve the first frame of our game (Environment)
- Based on state S0, Agent takes action A0 – our agent moves forward
- Environment goes to a new state S1 – new frame
- Environment gives some reward R1 to the Agent, (+1 reward for not failing)
An overall RL loop outputs a sequence of state, action, reward and next state. (S0, A0, R1, S1)
Reward Hypothesis
- RL is based on the reward hypothesis, which can be defined as maximization of the expected return (cumulative reward)
Markov Property
- Based on Markov Decision Process, is a discrete-time stochastic control process which provides a mathematical framework to describe an environment in reinforcement learning.
- Markov process in the future depends only on the present state and does not depend on past history
- Does not remember the past if the present state is given
- Our agent needs only the current state to decide what action to take and not the history of all the states and actions they took before
Observation/State Space
- The information our agent recieves from the environment.
- State is a complete description of the state/situation of the world (no hidden information)
- Observation is a partial description of the state. (eg, current frame of a mario level where a full map cannot be observed)
Action Space
- Set of all possible actions in an environment
- Discrete space - number of possible actions is finite(eg, mario has 4 directions and a jump)
- Continuous space - number of possible actions is infinite?
Type of Tasks
- Episodic Task - Has a starting point and an ending point (a terminal state)
- This creates an episode: a list of states, actions, rewards and new states. (eg, in a mario level, episode begin at the launch of new mario level, and ends when you’re killed or reach the end of the level).
- Continuous tasks - Tasks continue forever (no terminal state).
- In such an example, an agent must learn how to choose the best actions and simultaneously interact with the environment (eg, automated stock trading (no start point or terminal state) - Agent runs until stopped)
Rewards and discounting
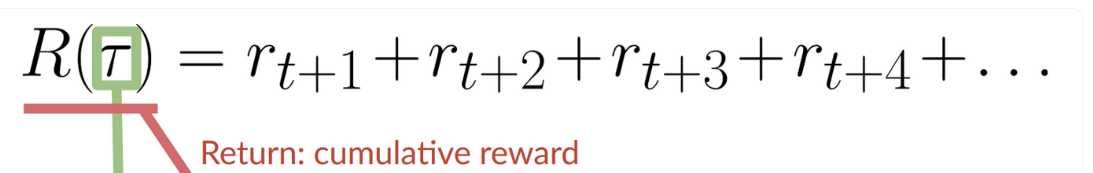
- Reward is the feedback for the agent to decide if the action taken was good or not.
- Cumulative reward, as shown above, is the total reward gained by the agent per episode run.
- However, we cannot add all rewards in this manner as the rewards that come sooner(at the beginnning of the game) are more likely to happen since they are more predictable than the long-term future rewards, and this messes up the overall episode reward calculation as the agent prioritises these rewards to late episode rewards.
Discounting
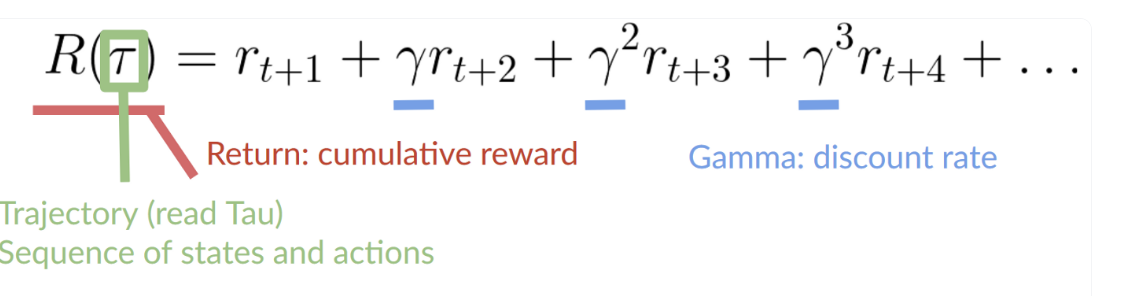
- To counter the above problem, we define a discount rate called gamma. Between 0 and 1 (0.95<x<0.99)
- Larger the gamma, smaller the discount. This means our agent cares more about the long-term rewards.
- Smaller the gamma, bigger the discount. This means our agent cares more about the short term rewards.
- Overall, each reward will be discounted by gamma to the exponent of the time step. As time steps increase, the future reward is less and less likely to happen, as shown in the picture above.
Exploration / Exploitation tradeoff
- Exploration is exploring the environment by trying random actions to find more information about the environment.
- Exploitation is exploiting known information to maximize the reward.
- Again, the goal of our RL agent is to maximize the expected cumulative reward. However, this can lead to a common trap, as explained below:
Example for this tradeoff trap (Choice of restuarant)
- Exploitation - You go to the same restuarant everyday as you know the food is good, therefore take the risk to miss out on a better restuarant. (Use known information to maximize the reward)
- Exploration - You try various restuarants you’ve never visited, but take the risk of having a bad experience but a higher chance of an overall positive result. (Try random actions to find more information about the environment)
RL Agent’s brain: Policy π
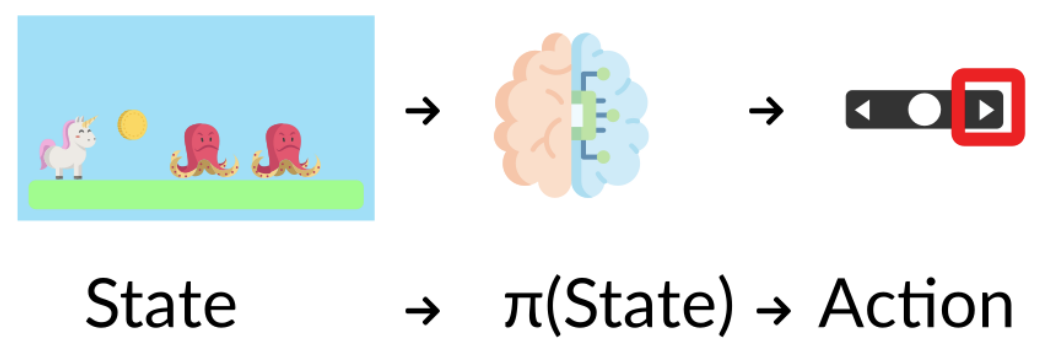
- This function tells the agent what action to take given the current state its in.
- To calculate the optimal policy to solve a problem, this function is calculated as it provides the maximum expected reward value for an action.
- Through training, two methods are devised to solve a RL problem:
- Policy-Based methods
- Value-Based methods
Policy-Based method
- We learn a policy funciton directly, where this function will map for each state the best corresponding action at that state.
Deterministic Policy

- This policy at a given state will always return the same action.
Stochastic Policy

- Whereas, this policy outputs a probability distribution over actions.
Value-Based method
- Here, instead of training a policy function, we train a value function that maps a state to the expected value of being at that state.
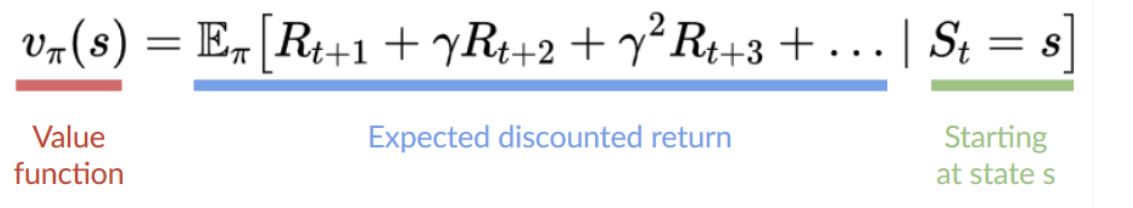
- The value of a state is the expected discounted return the agent can get if it starts in that state, and then acts according to our policy (going to the state with the highest value).

Overall provided summary
- Reinforcement Learning is a computational approach of learning from action. We build an agent that learns from the environment by interacting with it through trial and error and receiving rewards (negative or positive) as feedback.
- The goal of any RL agent is to maximize its expected cumulative reward (also called expected return) because RL is based on the reward hypothesis, which is that all goals can be described as the maximization of the expected cumulative reward.
- The RL process is a loop that outputs a sequence of state, action, reward and next state.
- To calculate the expected cumulative reward (expected return), we discount the rewards: the rewards that come sooner (at the beginning of the game) are more probable to happen since they are more predictable than the long term future reward.
- To solve an RL problem, you want to find an optimal policy, the policy is the “brain” of your AI that will tell us what action to take given a state. The optimal one is the one who gives you the actions that max the expected return.
- There are two ways to find your optimal policy:
- By training your policy directly: policy-based methods.
- By training a value function that tells us the expected return the agent will get at each state and use this function to define our policy: value-based methods.
- Finally, we speak about Deep RL because we introduces deep neural networks to estimate the action to take (policy-based) or to estimate the value of a state (value-based) hence the name “deep.”
Stable Baselines3